

# DBMS
→ DBMS stands for Database Management System.
→ We can say DBMS is a collection of data which is a set of program to store and retrieve those data.
→ DBMS is a collection of data and set of program to access and store those data in an easy and efficient manner.
→ DBMS is a software which is used to manage database.
→ Example: MSql, Oracle etc are popular commercial DBMS used in different application.
# Purpose of DBMS
→ Previously data is stored in files or registers. So many issues were faced in this kind of data storage.
1.) Data Rdundancy & Inconsistency :-
→ Multiple file formats, duplication of information in different files.
2.) Difficulty in accessing data :-
→ Need to write a new program to carry out each new task.
3.) Data Isolation :-
→ Multiple files and formats.
4.) Data Security.
5.) Transaction problems.
so, Database System offers solution to all the problems which is mentioned above.
# What is Database ?
→ It is a collection of data.

# Components of DBMS
→ user <-> software <-> hardware <-> data
1.) Users:- Application programmers, end users and data administrator.
2.) Software:- Controls the organization storage, management and retrieval of data in database.
3.) Hardware:- Hardwaere of a system can range from PC to a network of components. It also include various storage devices like harddisk and input devices like monitor, pointer, etc.
4.) Data:- Data Stored in database include, numerical data, non-numerical data, logical data.
# Building Blocks of Database
a.) Columns/Fields
b.) Rows/Tuples/Records
c.) Tables
# Advantages of Database
1.) Data Independence.
2.) Efficient Data Access.
3.) Data Integrity & Security.
4.) Data Administration.
5.) Concurent Access & Crash Recovery.
6.) Reduce application development time.
# Application of database
a.) Banking :- Manages the records of transactions.
b.) Airlines :- Manages reservations & schedule.
c.) Universities :- Manage the records of registrations, grades, etc.
d.) Sales :- Manages the records of customers, products, purchases.
e.) Maufacturing :- Production, Inventry orders, Supply chain.
f.) Human Resources :- Manages the records of employes informations like salary, taxes etc.
g.) Telecommunications :- Manages the records of calls, monthly bills.
# Disadvantages of database
- The overhead cost of using DBMS, because initial investment in hardware & software & training.
- Cost of defining and processing data.
- Overhead for security, concurrency cntrol, recovery.
- It may be more desirable, to use regular files under simple, well defined database app that are not expected to change. Also no multiple user access to data.
# Architecture of DBMS
- There are three level of Architecture of DBMS.
1.) External level/View level.
2.) Conceptual level/logical level.
3.) Internal level/Storage level.
1.) External level :- This level describes that part of Database that is relevant to each user.
2.) Conceptual level :- This level describes what data is stored in database and relationship among.
→ It represents all entities, attributes and their relationships.
→ It represents constrains on the data.
→ It also represents the security and integrity informations.
3.) Internal level :- It is physical representation of database. This level describes how the data is stored in database, it also covers the data structures and file system organization.
# DBMS can be seen as either single tier or multitier.
# An n tier architecture divides the whole system into related but independent n module.
1.) 1 - tier architecture :-

→ Only user Interface.
→ Presentation service.
→ Application service.
2.) 2 - tier architecture :-

→ It is client - server side architecture.
→ It has direct communication.
→ Run faster.
3.) 3 - tier architecture :-

→ It seperates tier from each other based on complexity of the user and how they use the data present.
→ It is a web based application.
→ There are three layer in architecture.
1.) Client Layer 2.) Business layer 3.) Data Layer
# Database (Data tier) :-
→ It resides along with its query processing languages.
# Application (Middle tier) :-
→ For a user, this presents an abstract view of database.
→ It acts as mediator between user and database.
# User (Presentation tier) :-
→ End user operator on this tier and they know nothing about any existence of database beyond this layer.
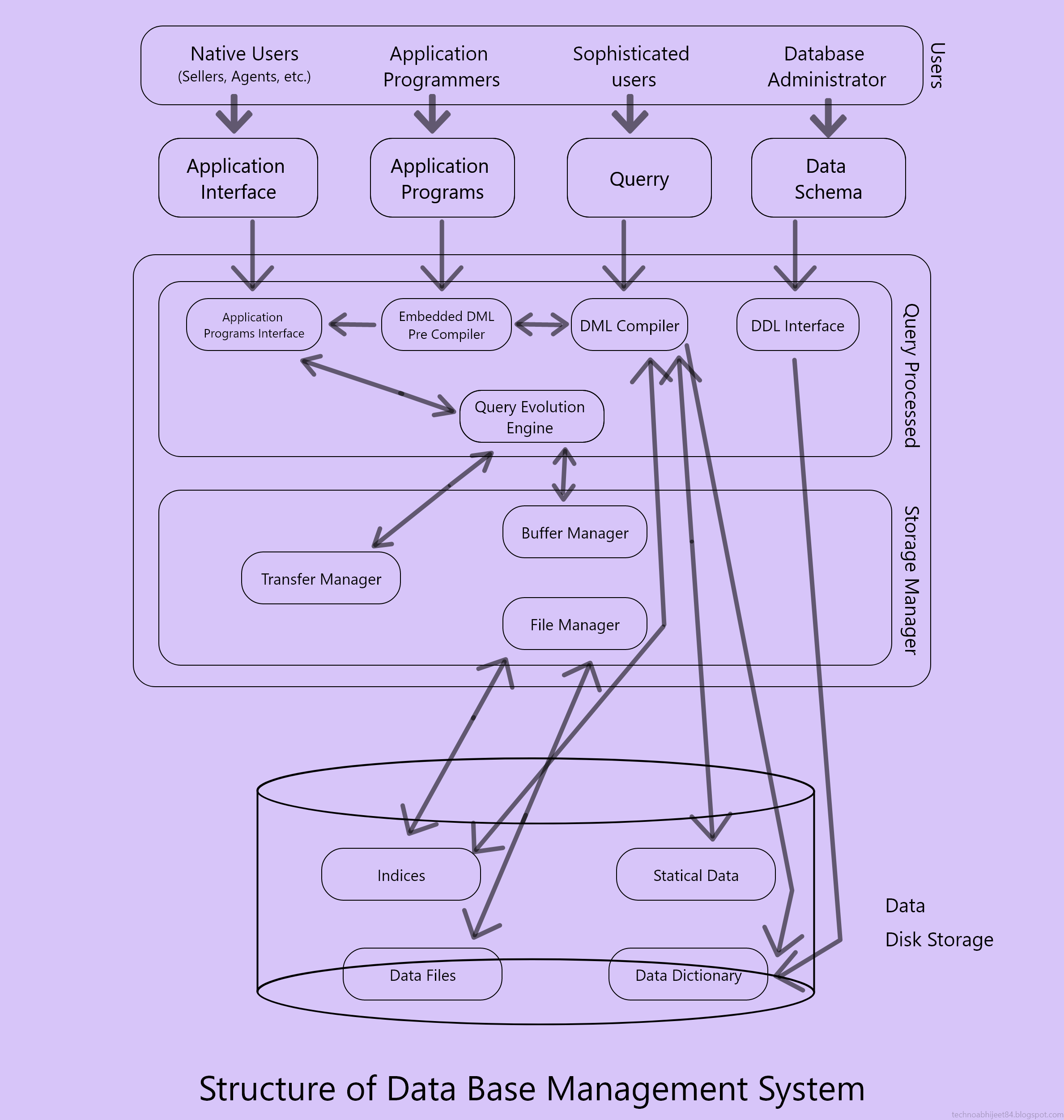
# Database User & Administrator
1.) Native Users
2.) Application Programmers
3.) Sophistcated Users
4.) Speciaized Users
5.) Online Users
1.) Native Users:- These users who do not need to be aware of the presence of datbase system. These are end users of database who work through menu driven application.
2.) Application Programmers:- They are responsible for developing application programs or user interface. Application programs will be written in high level language.
3.) Sophistcated Users:- Those who are interact with the system without writting the program. They request data using query languages.
4.) Specialized Users:- Who writes specialized database app that do not fit into fractional database processing frame work.
5.) Online Users:- Those users who communicate with database directly through online.
# Data Base Administrator:-
→ It is a group of incharge for implementing database system. The Database Administrates has all privilages allowed by the Database Management System and can assign or removes the privileges from the users.
# Data Independence
→ It is a capacity of changing the schema at one level without affecting the other.
→ DB System are designed in multilayer.
→ DB system stores data about data, known as meta data. Meta data always follows a Layerd architecture.
Note:- When it following layerd architecture, It changes in one layer, It did not affects other layer, so our data will be mainted well, so the data is independent. But all the data are mapped each other
# There are two types of Data independence
1.) Logical Data Independence
2.) Physical Data Independence
- logical schema → logical data independence
- Physical Schema → Physical data independence
Note:- Schema is the description of database.
1.) Logical Data Indepence:-
→ It stores information about how data is managed inside Database.
→ It has ability to change logical schema without affecting / changing the external or application, program.
→ It is also known as conceptual schema.
2.) Physical Data Indepence:-
→ It has ability to change the physical data without impacting the logical data / external Schema.
→ It also known as internal schema.
→ Eg: Change in external scheme, different file organization Storage devices structures should be possible withent affecting on changing the conceptual external Schema.


# Attributes
→ There are are the properties which define entity type and entities are represented by means of their properties is called attribute.
→ Entity: It may be an objects with physical existence or it may be an object with conceptual existence.
- Entity type: An entity of is an object of entity type
- Entity set: It is a set of all entities also we can say groups of entities.
→ Eg:- Roll, Name, DOB, Age , Address are the attributes which defines entity type student.

Note:- There exists a domain or range of values that can be assigned to attubule.
Eg:- Student name cannot be numeric
Student is char datatypes.
Age cannot be negative
# Types of Attributes
1.) Simple Attribute
2.) Composite Attribute
3.) Derived Attribute
4.) Single Valued Attribute
5.) Multi Valued Attribute
1.) Simple Attribute:- These are atomic values, which cannot be divided furthes. exor Student, phone no atomic value
Example:- Student -> Age (atomic value)
Atomic -> value (atomic value)
2.) Composite Attribute:- These can be divided into smaller sub parts.
eg :-

3.) Derived Attribute:- These attribute do not exist in the Physical database, but their values are derived from other attribute present in db.
.png)
with the help of birthdate we can know the age so we can say age is desired
attribute
4.) Single Value Attribute:- Contains only single value.

5.) Multi Value Attribute:- It may contains more than one values.
Eg:- Person can have more than one phone numbers.
Person can have more than one email Address.


# ER Model to Relational Model
→ Some of the methods are automated and some of them are manual.
→ ER Diagram maundy comprise of
1.) Entity & ito attributes
2.) Relationship which is association among entities.
→ These Relational model is Represented by Mapping entity.
1.) Create tables for each entity
2.) Entities attributes should become fields of tables with respective datatypes.
3.) Declar Primary key.
# Mapping Relationship
→ Relationship is an association among entities.

Steps for mappings
1.) Create a table for a refationship.
2.) Add primary key of all participants entities as fields.
3.) If relationship has any attributes then add each attributes as field of a table.
4.) Declare primary Key.
5.) Declare Foreign key constrants.
# Mapping weak Entity Set
→ A weak entity set is one which does not have any primary key associated with it.
Mapping process
1.) Create table for weak entity set.
2.) Add all attributes to table as fields.
3.) Add primary key of identifying entity set.
4.) Declare foreign key constraint.

# Mapping Hierarchical Entity
→ ER specilization and genreralization comes in the form of hierarchical entity sets.
Mapping process
1.) Create table for all higher entities and lower level entities.
2.) Add primary key of higher level in the table of lower level entities.
3.) In lower-level tables, add all other attributes of lower level entities.
4.) Declare primary key of higher level table.
5.) Declare foreign key constraint.

1.) Generalization :- Number of entities brought in one entities based on their similar characteristucs.

2.) Speclization :- It is just opposite of generalization. Groups of entities divided into sub groups based on their characteristics.

# Relational Model
→ A relation is a table with columns and rows.
→ It is based on the mathematical cocepts of relation which is represented physically as table.
→ The main use of the table relational model is to data storage and processing.


Q. How to find the Degree of Relation ?
→ Number of attributes in a relation is called degree.
Q. How to find the cardinality of Relation ?
→ Number of tuples in a relation is called Cardinality.
# Properties of relation
1.) The relation has name that is district from all the names in the relationship schema.
2.) Each cell of the relation contains exactly one value .
3.) Each attribute has district names.
4.) Each type is District there are no duplicate tuples.
5.) The Order of attribute has no significance.
6.) The order of tuples has no significance.
# Constraints (condition)
→ Every relation has some condition that must hold for it to be a valid relation,called relational Integnity Constraints.
→ There are three contraints in DBMS.
1.) Key constraints/entity constraints.
2.) Domain Constraints.
3.) Beflerential Integrity constraints.
1) Key constrains:-
→ In a relation with a key attributes no 2 tuples can have identical value in keys attributes.
→ Key attribute can not have null values.
→ If there are more than one such minal Subsets, these are called Candidate keys.
2) Domain Constraints:-
→ Every attribute is bound to have a specific range of values.
→ Eg:- Age cannot - ve or less than zero phone number should be 0-9.
3) Refferntial Integnity constraints:-
→ It work on the concept of foreign keys.
→ A foregin key is a key attributes of arelation,that can be reffered in other relation.
# Keys in DBMS
→ It is a attributes or set of attributes which help us to identify a rew (tuple).
→ It also allows us to find the relation bt4 two tablets.
→ Eg:-
→ To fetch a particular records from a huge DMMS we need key's
# Types of keys
1) Primary key
2) Candidate key
3) Super key
4) Foregin key
1.) Superkey:-A super key is a set of attributes that can identity each row uniquely. Super key unsist of any no of attributes.
eg:- std(roll, name, sex, age, add, class, section)
→ (roll, name, sex, age, add, class) → superkeys
→ (class, section, roll) → super keys
→ (class, section, roll, sex) → super keys
→ (Name, add) → super keys.
2.) Condidate key:- A mimal super key is clled candidate key.
3.) Primary key:- It can never be null always unique,updation is not possible.
4.) Foreign key:- Defines Relationship with another Tables.
1.) Super Key:-
→ It is defined as a set of attributes with a table that can uniquely identify each records within a table.
→ Super Key is a superset of candidate key.
Student Table
.png)
i.) std-id is unique in every row of date,hence it can be used to identity . each row uniquely.
ii.) stdid,Name name of two student can be same,but there id carit be same ,hence this combinate is also be a key.
iii.) Phone no is also unique, hence it can also be key.
2.) Condidate key
→ A Super key without redundancey.
→ It is not reducible further.
→ Minimum set of attributes used to uniquely differentiate reward of the table single or Combination of Minimal attributes.
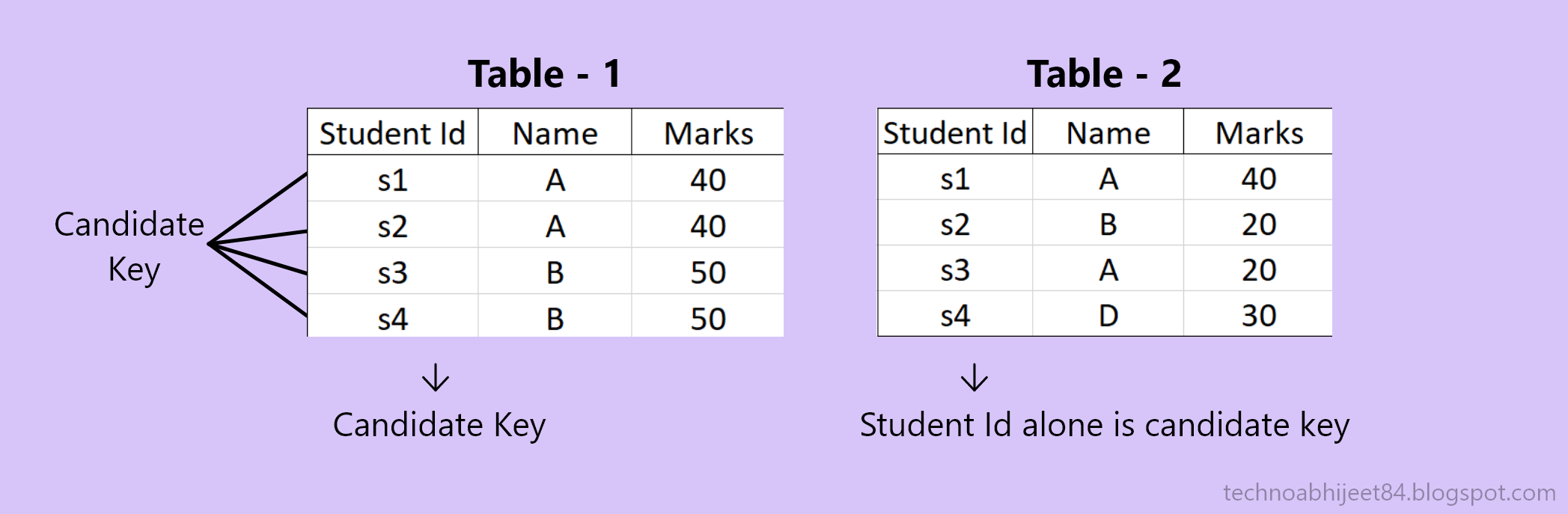
→ A candidate key can never be NULL or empty and its value should be uniqe.
→ There can be more then one candidate key a table .
3.) Primary key
→ It is a candidate key that is most appopiate to become the main key for any table.
→ It is a key that can uniquely identify each record in a table.
→ eg:-

→ Primary key contain unique values must never be NULL.
→ It unique identify each record in table.
Note:-
→ Primary key are Mandatory for table each record must have a value for its primary key.
→ When choosing a primary key from the pool of Candidate key always choose single key over a composite key.
# Foreign key
→ It is an attribute which established relationship btn2 tables.
→ Foreign key is a field/collection of field in one table that refers to the primary key in another tables.
→ eg:-

→ we can say foreign key is responsible for connection between two tables.
→ Records cannot be inserted into a detail tables if corresponding record in the master table does not exits.
→ Record of master tables cannot be deleted if Corresponding records in the detail table actually exixts.

- Parent must be unique or primary key.
- Child may have duplicate/null unless it is specified.
- Constraint specified an child not in parent.
- Parent record can delete only if no child record exists.
- Parent cannot modity if child record exist.
# Secondary key
→ It is also know as alternate keys
→ We use it for indexing purpose for better & fast searching.
→ The candidate key other than a primary key is called Alternte key.


# Composition key
→ A key which has multiple attributes to uniquely identify raws in a table is called composite key.
→ But the attributes which together form the composite key are not a key independently or indivisually.

Here std-id & subject-id together will form the primary key.
# Relational Algebra
→ It is used in the designe of transaction & forms the conceptual basis of SQL.
→ It consist of operators &manipulators which apply to relations & give relation as a result but do not change the actual relation in db.
→ It is a procedural intermediate language used with in the DBMS.
<Figure.......>
# Advantages of relational Algebra
→ Mathematical background is the basic of many interesting development & basic of many interesting development & theorems.
→ Query optimizer substitute most efficient query.
Normalization & Redundary
<Figurw..........................>
# Insert Anomolies
-> Attributes cannot insert with thw presence of other attributes.
or,
we tried to insert data in record that doesnt exits at all.
# Delete Anomolies
→ Exists when certain attributes are lost because of deletion of one attributes.
# Update Anomolies
→ Partial update because of data inconsistency.
# Normalisation
→ Nornmalisation is a method to remove all these anomalies & bring the db to a consistent State.
# Normal Forms
→ Condition using keys & functional dependence of a relation to certify whether a relation schema is in a particular Normal form .
* 2NF,3NF,BCNF based on keys & FD'& of a relation schema.
* 4MF is based on keys & multivalue dependencies.
<Figure.......>
# Characteristics of Normalization
→ Scalar values in each fields.
→ Minimal use of Null value.
→ Absence of redundancy.
→ Minimal loss of information.
# First Normal Form (INF)
→ It is a property of a relation in relation db.
→ All attributes in a reltion must have only atomic (indivisible)domains.
# Requirement for INF
1.) Each tables has primary key minimal set of attribute which can uniquely identity a reward.
2.) The value in each coloum of a table are atomic (no multivalve attributes are allowed).
3.) There are not no repeating groups are allowed.
4.) It means two coloum o not store similar information in same information.
# 1NF Decomposition
a.) Place all items that appears in the repeating group in a new table.
b.) Designate a primary key for each new table produce.
c.) Duplicate in the new tabe the primary key of the table from which repeating group was extracted or vice versa.



 ){kind=link}
0 Comments
Thank You ! For your love